【引言】
在工业上的抓取作业中,多数情况下会有:待检测物体类型单一、物体模型表面纹理较少、工件散乱且密集、金属表面(油污、反光)影响成像效果等作业环境上的特殊性条件存在。针对不同的应用场景及作业需求,需要有的放矢地选择一种合适的位姿估计方案,以提高后续机器人的抓取成功率及作业的整体效率。
现阶段,针对刚性物体的位姿估计方法,大致可以归为以下三类:
1 基于模板匹配
2 基于3D描述符(描述子)
3 基于学习(神经网络/ end to end)
一、基于模板匹配的方式
在可能的三维空间区域中,将待检测物的三维模型进行不同视角下的渲染成像,提取各视角下物体的相关信息(如:轮廓、边缘梯度、表面曲率等),对待检测物体进行充分的采样,提取足够鲁棒的模板集。匹配时,从场景中提取相关信息,并在建立好的模板集中进行查询比对,找到相似度最高的模板,并以该模板的位姿作为粗位姿,然后结合ICP等方式进行位姿的细配准。
论文示例
《Real-Time 6D
Object Pose Estimation on CPU》[1]
该方法以模板匹配为基本原理,从特征集模板的构建、模板的存储数据结构以及内存重组优化等三个方面作出了改进和优化工作,以提高配准的准确度及整个流程的速度。
01 模板特征集的构建
从多个视角对工件的CAD模型进行投影成像,并对每一个投影数据构建PCOF(Perspectively Cumulated Orientation
Feature)特征集(每个视角对应一个模板位姿)。

特征集在构建时,同时使用投影点云的表面法向及轮廓梯度方向信息创建方向直方图(共8个方向),并按照阈值将直方图进行二值化(组频率大于阈值的置为1),最后用一个字节(byte)来存储(一个byte共8个bit位,对应8个方向)。
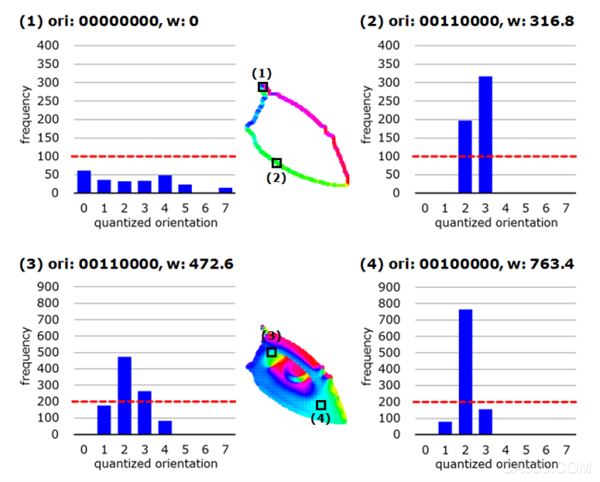
方向直方图示例,ori(二值化的方向直方图),w(权重,以该直方图中超过所设阈值的最大频率来表示):
1,2两像素点取自投影图像的轮廓,以梯度方向构建直方图
3,4两像素点取自投影图像表面,以法线方向构建方向直方图
02 使用BPT数据结构存储构建的模板
在对模型进行投影成像时,视角点的选取是通过将正二十面体(下图中depth 0)不断等分,最终形成正1280面体(下图中depth 3),然后均匀选取正1280面体的顶点作为模型投影成像的视角点。
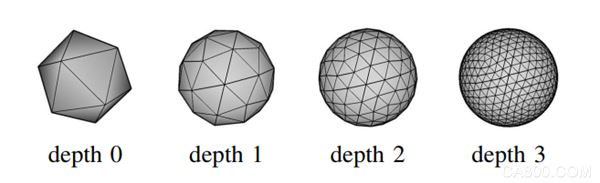
填充构建”树”型存储结构时,从第3层(depth 3)开始,实际的成像视角点也是从第三层选取,依次从上一层找到分割时的“父节点(顶点)”,并使用当前层中所有属于该“父节点”的模板位姿的均值作为“父节点”的位姿;
递归处理,直至第0层(depth 0),以此创建一个4层的、由“粗”到“细”的模板位姿树(BPT(Balanced Pose Tree))
将创建的模板按照“树”型结构进行分层存储(共四层),查找时,实现由“粗”到“细”的模板搜索方式,以便加速模板的匹配查找,得到粗位姿。
03 利用SIMD技术实现内存重组
结合“树”型数据存储结构,利用SIMD(Single Instruction Multiple Data)技术实现内存重组,以达到加速的目的。
该方法示例效果:

该方法分别在桌面场景(左图)
及无序抓取场景(右图)下的测试效果
二、基于3D描述符(描述子)
三组对应点即可解析得到两模型之间的对应位姿,所以,利用法向量、点间距等数学语言描述出模型表面的线条、边缘等多种局部特征,进而找出准确的对应点。在得到匹配的点对之后,再结合随机采样一致性(RANSAC)或者霍夫投票(Hough voting)等方式得到局部最优解,以此作为模型配准的粗位姿,最后利用ICP等方式进行精化得到最终结果。
论文示例
《Model
Globally, Match Locally: Efficient and Robust 3D Object Recognition》[2]
该方法提出了一种新的局部描述符——PPF(Point Pair Featrue),通过对待匹配工件的点云中,任意两个数据点之间构建PPF特征,最终形成一个该工件模型整体的PPF特征集。在实际匹配时,从场景点云中选取参考点,以该参考点为中心,与周围的数据点构建PPF特征,并将该特征与模型特征集中的数据作匹配,然后利用霍夫投票的形式,得到场景点云中该参考点所属工件的粗位姿,最后再利用ICP等方式进行位姿的细化配准。
01 构建模型的PPF特征集(Model Globally)
整体建模,构建对模型的全局描述,其中“Globally”是指对整个模型点云进行特征(PPF,Point Pair Feature)的计算,然后将所有计算得到的特征集存储在Hash表中,以供后续匹配时查询使用。(离线阶段完成)
Model Globally 的本质是通过定义 Point Pair Feature,来构建特征矢量的集合以及每个特征矢量对应的“点对”集,作为 Global Model Desciption。
PPF 描述了两个有向点(oriented points)的相对位置和姿态。假设有两个点 m1 和 m2 ,法向量(normals)分别为 n1 和 n2 ,d = m2 - m1 (有向线段) ,则 PPF 定义如下:
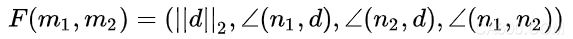

( 即 F(m1,m2) ≠ F(m2,m1) )
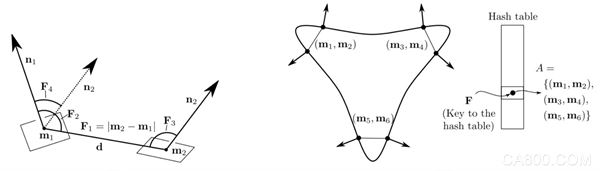
m1为该PPF(m1, m2)中的参考点,n1,n2分别为各自的法向量;
点对特征PPF(m1,m2) = (F1, F2,F3,F4);
由于存在具有相同PPF特征的多个点对,所以同一个hash表索引可能对应多个特征点对
02 通过Hash表查询,进行投票匹配(Match Locally)
局部匹配,从场景点云中选取参考点,并与周围数据点构建PPF特征,然后到hash表中查找是否存在一致的特征值,由于是以场景的单个点对特征到模型的全局描述(hash table)中进行匹配,所以称为“局部”匹配。
其中,恒定坐标系为整个匹配流程的核心概念,由于模型及场景点云中每个数据点都是法线已知,故将“模型点对”与“场景点对”各自旋转,使其参考点的法向与恒定坐标系X轴已知,且参考点的位置与恒定坐标系原点重合,得到各自的变换矩阵(RT) Ts-g和Tm->g;当“场景点对”与“模型点对”同处于恒定坐标系下时,将“模型点对”绕X轴旋转,使其与“场景点对”重合,得到旋转角度值α,接着以该模型点的索引与α值,在累计投票表中进行投票。(参考图示如下)
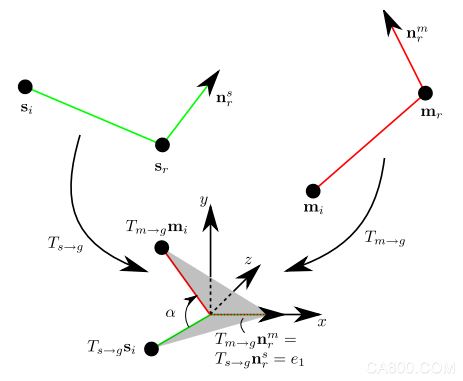
PPF(mr, mi) 为“模型点对”,mr为模型参考点
PPF(sr, si) 为“场景点对”,sr为场景参考点
PPF特征中的法线方向,皆为参考点的法线方向
构建的“场景点对”需要与有相同Hash索引的所有“模型点对”进行上述投票处理,故每一个“场景点对”都会生成一张投票表,其中,行数与模型点数相同,且与模型索引值一一对应;列数为划分的角度数目,该方法中共划分为30份,以(π/15)为角度间隔。(参考图示如下)
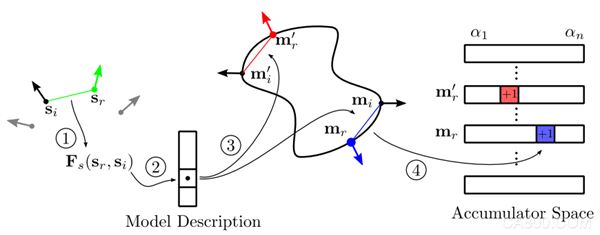
从Hash表中搜索与“场景点对”具有相同Hash索引的“模型点对”,然后进行累计投票
03 提取粗位姿
根据上述流程中统计得到的累计投分表寻找分值大于所设阈值的位置。由于我们已经得到了“场景点对”及“模型点对”各自旋转到恒定坐标系下的变换矩阵,以及“模型点对”绕X轴旋转到“场景点对”的旋转角度α,故可以计算出模型旋转到场景中工件位姿的变换矩阵,即:
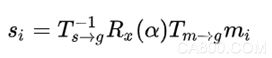
04 位姿聚类
每个参考点都可能会返回多个位姿(分值相同或多个分值大于所设阈值的位姿),对所有返回的位姿进行聚类,将位姿差异不超过所设阈值的位姿归为同一类,然后对每个聚类中的位姿取均值,依次代表该聚类的位姿,其分值为聚类中所有位姿的总分值,最后比较所有聚类的分值,将分值最高的聚类位姿作为配准得到的位姿输出。
该方法示例效果:


在遮挡及噪声场景下的测试
经物体识别与位姿估计后,模型以网格的形式展现,以作对比
三、基于学习(神经网络)
这类方法也可以叫作基于回归的方法。从模型的三维点云数据或投影到多个视角下的的图像数据中寻找位姿和图像之间的内在联系。常见的基于学习的方法可分为两类,一类是直接回归出物体的6D位姿(语义分割->Translation估计-> Rotation估计);另一类方法是先估计3D KeyPoint在2D图像上的投影点,然后使用PnP(Perspective-n-Point)等算法方式对位姿进行恢复。
论文示例
《PoseCNN: A
convolutional neural network for 6d object pose estimation in cluttered scenes》[3]
在传统的物体识别与位姿估计方式中,存在对于弱纹理、对称以及有遮挡的物体的识别及位姿估计能力相对较弱的情况,针对这些问题,该方法提出一种端到端(end to end)的用于6D目标姿态估计的新型卷积神经网络PoseCNN。PoseCNN通过在图像中定位物体的中心并预测其与摄像机的距离来估计物体的三维平移。通过回归到四元数(w,x,y,z)表示来估计物体的三维旋转。其主要任务有三项:语义分割、3D平移估计、3D旋转估计。此外,还引入了一种用于对称物体姿态估计的新训练损失函数ShapeMatch-Loss,并提供了一个大规模的RGB-D视频数据集(YCB-Video dataset),用于6D物体姿态估计。
网络架构
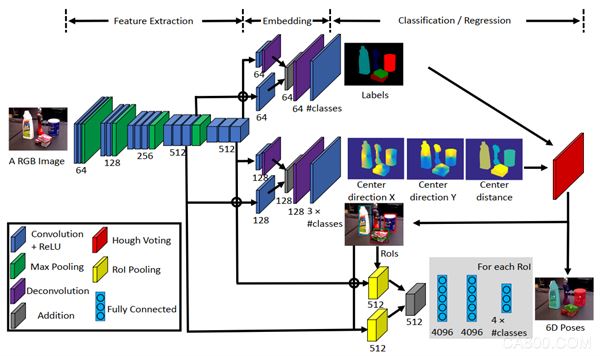
该网络共含有三个分支:语义分割分支、位置估计分支、姿态估计分支,每个分支都有一个loss函数,共三个。
01 位置估计分支
通过3D位置估计获得平移矩阵T=(Tx,Ty,Tz)(目标物体在相机坐标系下的坐标),一种简单的估计T的方法是直接将图像特征回归到T,但是由于目标可能出现在图像上的任意位置,因此这种方式是不可推广的。并且不能处理同类的多个目标实例。该方法通过定位2D图像的目标中心并估计目标到相机的距离来估计三维平移量。
(1)目标对象2D中心的预测(Hough Voting)
该层采用像素方式的语义标记结果和中心回归结果作为输入。对于每一个物体,首先计算图像中的每个位置的投票得分,其分值表明了相应的图像位置是物体的中心的可能性大小。物体的每个像素都会根据网络预测添加图像位置的投票,在处理完物体的所有像素后可以获得所有图像位置的投票分数,最后选择最高分的位置作为物体中心。
通过如下公式,可以恢复得到位置平移矩阵中的Tx和Ty:
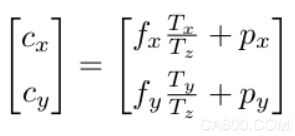
fx、fy表示相机焦距,(px,py)是主点,c是目标的二维中心
(2)深度预测Tz
生成了一系列目标中心之后,将投票给目标中心的像素视为该中心的初始值。然后,中心深度Tz的预测,被简单地计算为由初始值预测的深度的平均值。
02 姿态估计分支
在Hough投票层可以预测得到的物体对象2D BBox,同时利用两个RoI池化层对网络第一阶段生成的视觉特征进行剪裁和池化,然后进行3D旋转回归,得到目标对象的旋转变换。
为了对四元数进行回归训练,该方法提出两个损失函数:
1、PoseLoss(PLoss),正确模型姿态上的点与相应使用估计方向上的点的平均平方误差。
2、ShapeMatch-Loss(SLoss),不需要对称规范,估计点与真值最近点的损失测量。
该方法示例效果:

分别在YCB-Video和OccludedLINEMOD数据集上作测试,
由上至下分别为:输入数据、语义分割及中心点标注后的结果、
仅使用RGB数据、使用RGB-D数据并使用ICP进行位姿细化
参考文献:
[1] Yoshinori Konishi, Kosuke Hattori,
and Manabu Hashimoto. Real-time 6d object pose estimation on cpu. IEEE/RSJ
International Conference on Intelligent Robots and Systems (IROS), Macau,
China, 2019, pp. 3451-3458
[2] B. Drost, M. Ulrich, N. Navab, and S.
Ilic. Model globally, match locally: Efficient and robust 3d object
recognition. IEEE Computer Society Conference on Computer Vision and Pattern
Recognition • July 2010
[3] Yu Xiang, Tanner Schmidt,
Venkatraman Narayanan, and Dieter Fox. PoseCNN: A convolutional neural network
for 6d object pose estimation in cluttered scenes. arXiv preprint
arXiv:1711.00199, 2017.
更多机器视觉产品信息与应用说明,机器视觉算法,应用技巧,解决方案以及相关领域的技术分享,欢迎继续关注“汉振智能”....